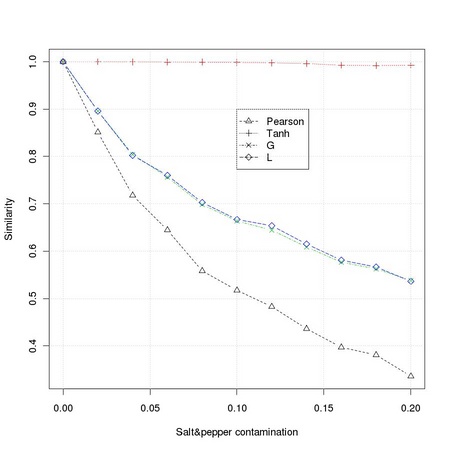
4.3 L1 similarity measures
While the robustness achievable with tm.robustifiedCorrelation is remarkable, there are two
related problems:
- it requires a substantial amount of computation;
- it can be, paradoxically, too robust: it looses discrimination efficiency.
Both problems can be solved using the similarity estimators based on the L1 norm as described in
Section TM:4.3.
1 tm.noiseSimilarityImpact <- function(img, cRange=c(0,0.2)) { 2 ... c0 <- cRange[1] 3 ... c1 <- cRange[2] 4 ... cs <- seq(c0,c1,(c1-c0)/10) 5 ... n <- length(cs) 6 ... # 7 ... img <- ia.scale(img) 8 ... res <- array(0, dim=c(n, 5)) 9 ... # 10 ... i <- 0 11 ... X <- tm.normalizeImage(img) 12 ... for(c in seq(c0,c1,(c1-c0)/10)) { 13 ... i <- i + 1 14 ... res[i,1] <- c 15 ... # 16 ... Y <- tm.addNoise(img, noiseType="saltpepper", scale = 1, percent=c) 17 ... Y <- tm.normalizeImage(Y) 18 ... # 19 ... res[i,2] <- tm.robustifiedCorrelation(X, Y, "p") 20 ... res[i,3] <- tm.robustifiedCorrelation(X, Y, "O") 21 ... res[i,4] <- max(ia.correlation(X,Y, type="G")[[1]]@data)/100 22 ... res[i,5] <- max(ia.correlation(X,Y, type="L")[[1]]@data)/100 23 ... } 24 ... # 25 ... res 26 ... }
1 f <- ia.get(img1, animask(32,87,104,104)) 2 nsi <- tm.noiseSimilarityImpact(f) 3 tm.dev("figures/robustCorrelation") 4 matplot(nsi[,1], nsi[,2:5], type="b", pch=2:5, lty=2:5, 5 ... xlab="Salt&pepper contamination", ylab="Similarity") 6 legend(0.1,0.9,c("Pearson", "Tanh", "G", "L"), lty=2:5, pch=2:5) 7 grid() 8 dev.off()