Fondazione Bruno Kessler - Technologies of Vision
contains material from
Template Matching Techniques in Computer Vision: Theory and Practice
Roberto Brunelli © 2009 John Wiley & Sons, Ltd
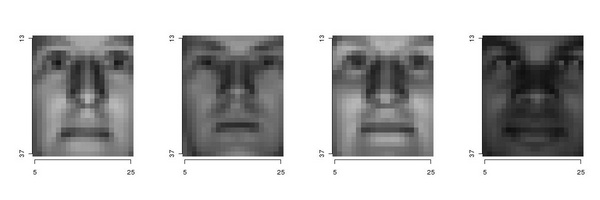
In this section we start to address the problems arising from intrinsic signal variability. We no longer limit ourselves to the the problem of detecting a single, deterministic signal corrupted by noise, and we move to the problem of detecting a class of signals in the presence of noise. The signals we will consider are images of faces, a class of patterns of significant practical and theoretical interest. The dataset we will be using comprises 800 different faces, equally distributed over four differents races and the two genders.
It is interesting to note the result of clustering the above data respectivel with 4 clusters, the number of races considered, and with 8 clusters the number of races times the number of genders:
The default metrics used by function clara is the Euclidean norm (L2) discussed in a previous chapter. Samples are regularly (consecutively) organized in groups of 200 items, 100 males and 100 females. The above clustering procedure, of which we reported the indices identifying each computed cluster within the original data, assigns 1 cluster center to each race (or race and gender) group.

|
As detailed in Section TM:6.1, the optimal matched filter for the whole image set is given by the dominant eigenvector. Let us note that, in this case, the required covariance matrix is the not-centered one:
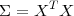 | (6.1) |
where X is a matrix whose rows correspond to our face images, linearized as vectors:
The computation of the eigenvectors is straightforward:

|