|
Fondazione Bruno Kessler - Technologies of Vision
contains material from
Template Matching Techniques in Computer Vision: Theory and Practice
Roberto Brunelli © 2009 John Wiley & Sons, Ltd
Template matching is the generic name for a set of techniques that quantify the similarity of two digital images, or portion thereof, in order to establish whether they are the same or not. Digital images are commonly represented with numerical arrays: monochrome images require a single matrix while color images require multiple matrices, one per color component. We will restrict our attention to monochrome images. Digital images can be stored in various formats such as jpeg, tiff, or ppm. A variant of the latter, specific to grey level images, is commonly identified with a .pgm suffix. Package AnImAl provides convenient functions to read them:
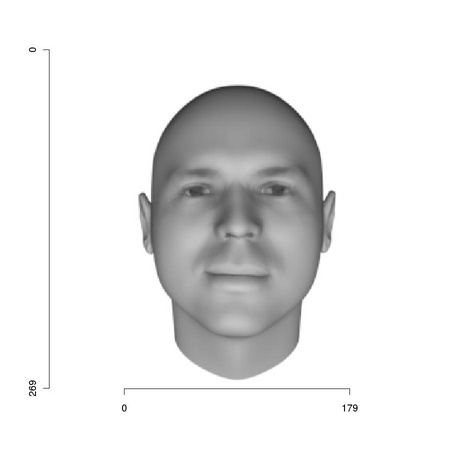
Note the darker region: it identifies R output. The coordinate system most often associated to an image is left-handed: the value of the x coordinate increases from left to right while that of the y coordinate increases from top to bottom (see Figure 1.1). This is due to images being stored as arrays and to the fact that the y coordinate is associated to the row number. R provides extensive graphical facilities and function tm.ploteps can be used to turn their output to postscript files:
Setting tm.plot.defaultFormat <- "X11" (uncommenting line 1 above) makes subsequent calls to tm.plot use the windowing system. We will routinely use tm.plot to produce the images inserted in this manual.
The existence of an image coordinate system allows us to specify in a compact way rectangular regions: we simply need to provide the coordinates (x0,y0) of its upper left corner and the horizontal and vertical dimensions (dx,dy):
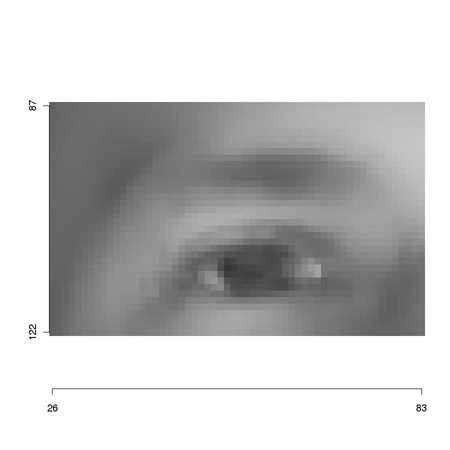
The result, reported in Figure 1.2, is a new, smaller image that carries on the knowledge of its original placement as the axes values show.
|
As clarified in Figure TM1.2, the search for a template, such as the one presented in Figure 1.2, within an image, such as the one in Figure 1.1, is performed by scanning the whole image, extracting at each image position a region of interest whose size corresponds to that of the template:
Function ia.show in line 4 of the above code snippet would show image portion w in a window. However, what we need to do is to compare each image w to the reference template eye1 assessing their similarity. We should also store the resulting values in a map so that we can access them freely after the computation is completed.
Codelet 1 Basic template matching (./R/tm.basicTemplateMatching.R)
____________________________________________________________________________________________________________
This function illustrates the most basic template matching technique: the template is moved over each image position and the sum of the squared difference of aligned image and template pixels is considered an indicator of template dissimilarity.
The first step is to get the linear dimensions of the template
We then determine the extent of the image region of interest over which we need to slide our template
This allows us to prepare the storage for the similarity scores
and to perform the actual computation loop,
sliding along each row and extracting in turn an image portion matching the size of the template
We modify the template so that it overlaps the extracted region
and compute (and store) the matching score
We can finally return the image representing the similarity map
______________________________________________________________________________________
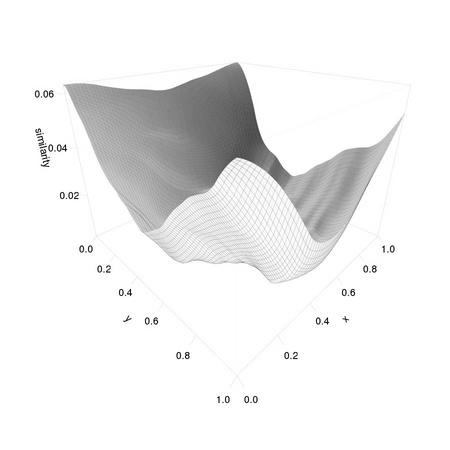
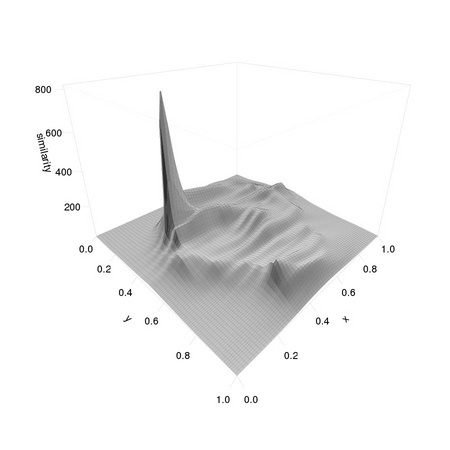
It is now easy to spot our template in the image:
Note that the position of the template differs from that of the original eye1 as we down-sampled the image: the coordinates are halved. We can also have a look at the resulting matrices to get an idea of how extremal the matching value at the correct position is: this is related to the concept of signal to noise ratio that we will consider in depth in later chapters.
|
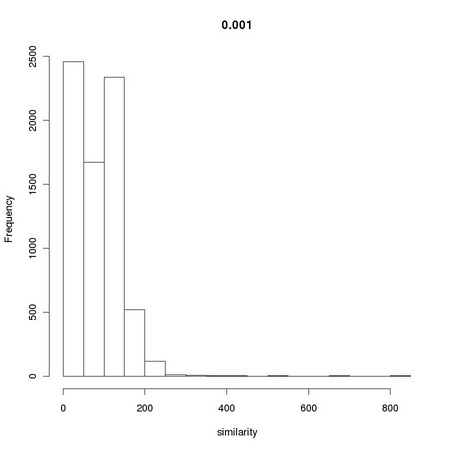
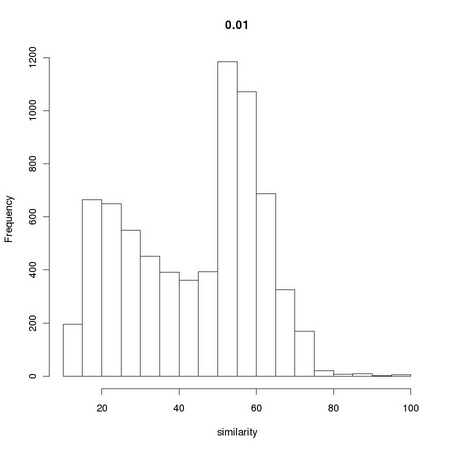
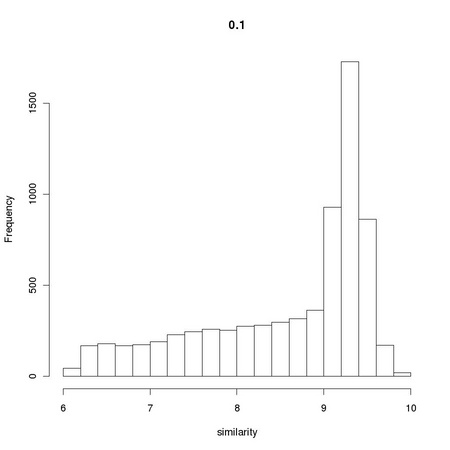
AnImAl provides ia.correlation, a faster and more flexible function to perform the task that will be considered in Chapter 3. Changing the value 0.001 used in the computation of simScores significantly affects the distribution of values:
The resulting distributions are reported in Figure 1.4.