|
Fondazione Bruno Kessler - Technologies of Vision
contains material from
Template Matching Techniques in Computer Vision: Theory and Practice
Roberto Brunelli © 2009 John Wiley & Sons, Ltd
The requirements of interactive image processing, particularly during the development of algorithms, are the same as those of the larger statistical community and of the even larger community of computational science. A good development environment should rely on a high level programming language with extensive facilities for the manipulation of the most commonly used data structures, the possibility of saving the status of a processing session for later continuation, extensive community support, and means for code verification and high quality documentation. Another important, often neglected, feature is the possibility of accessing the source code of the environment and of its libraries so that the appropriateness of the algorithms underlying the functions provided and the correctness of their implementation can be assessed. R, a language and environment for statistical computing and graphics, based on the system described in [?], fulfills all these requirements and has then been chosen as the programming environment for the implementation the image algebra described in Section TM:A.1. Nearly all of the algorithms described in the present book have been implemented in the R environment and are provided as an accompanying set of computer files with extensive documentation and examples.
What we would like to address in the following paragraphs is the extent to which such a development environment can support investigation based on the iteration of hypothesize, test, and refinement cycles, and the accurate reporting of results. The R environment supports selective saving of itself: objects, memory contents, and command history can be saved to be imported at a later date or visually inspected. The history mechanism provided by AnImAl extends these facilities by adding self documenting abilities to a specific data structure (the image) making it even easier to extract the details of every processing step in order to accurately document it. Accurate reporting of results, and of processing work flow, means that enough information should be provided to make the results reproducible: this is the essence of reproducible research. Traditional means of scientific dissemination, such as journal papers, are not up to the task: they merely cite the results supporting the claimed conclusions but do not (easily) lend themselves to independent verification. A viable solution in the case of computational sciences is to adopt more flexible documentation tools that merge as far as possible data acquisition, algorithms description and implementation, and reporting of results and conclusions. A useful concept is that of compendium: a dynamic document that includes both literate algorithms description and their actual implementation. The compendium is a dynamic entity: it can be automatically transformed by executing the algorithms it contains, obtaining the results commented upon by the literate part of the document. This approach has two significant advantages: enough information for the results to be reproducible by the community is provided, and results reported in the description are aligned to the actual processing work flow employed.
The R environment provides extensive support for the creation of compendiums: code such as
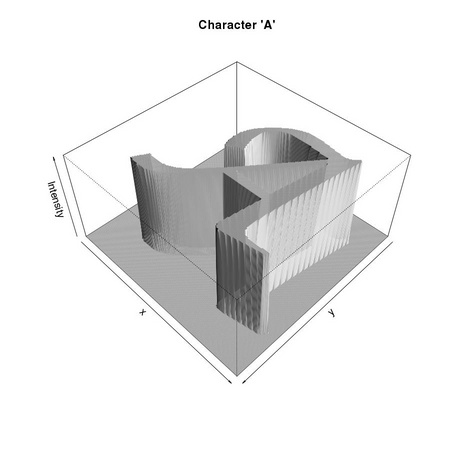
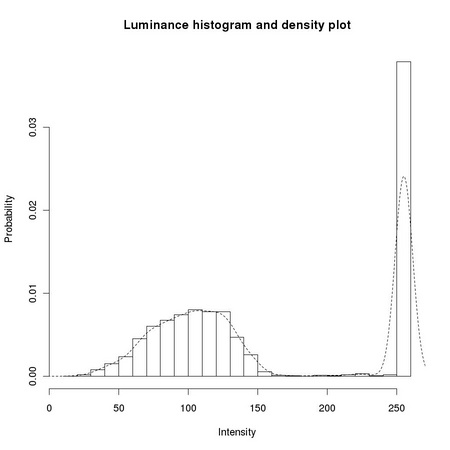
can be freely inserted within the text, with the possibility of hiding it in the final document. The code can be executed, and its results, be they pictorial (see Figures A.1–A.3), or numeric (see Table A.1), automatically inserted at the right places.
|
Literate algorithm descriptions can be inserted as comments in the source code and automatically extracted and formatted to match high quality scientific publication requirements. We report a simple example: the definition of an R function, based on AnImAl, for the computation of the boundaries of shapes in binary images. Insertion in the compendium of the directive
generates the literate description of the function reported in the next paragraphs by suitably formatting code and comments included in the function definition file.
Codelet 7 Edge detection for a binary image (../AnImAl/R/ia.edge.R)
____________________________________________________________________________________________________________
This is an example of how the basic bit level logical operators provided by AnImAl can be used to extend its functionalities. In this particular case we define a new function with name ia_edge and a single argument img:
The first step is to check whether image history must be updated in order to produce a coherent image:
We momentarily turn off self documentation as we want to consider the current function as a whole and we do not want its inner workings to be traced by the history mechanism:
In this particular case we fix the region of interest of the resulting image to that of the function argument. As subsequent operations may enlarge we store the initial specification of the region
A pixel is considered to be an edge pixel if at least one of the pixels to its left, right, top, or bottom belongs to the image background (value=0):
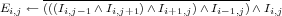
This logical formula can be easily implemented using the bit level logical operations provided by AnImAl:
If required by the configuration of the argument image img we update the history of the result image res to keep it coherent
In this case, it is necessary to update the tracing flag:
and to get the new root of the history tree which is given by the current function invocation:
We then need to expand the node corresponding to img with the corresponding history
so that complete history information can be stored in the resulting image:
before returning the final result:
______________________________________________________________________________________
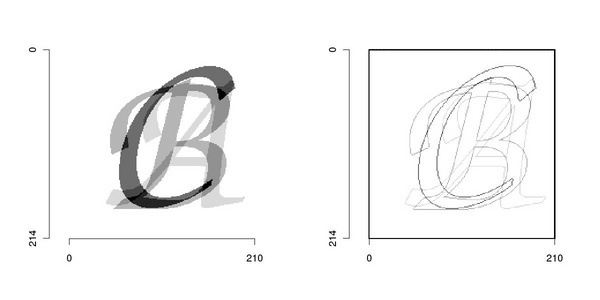
An example of the results provided by this function is reported in Figure A.3.
|
We did not comment so far on how data acquisition fits within the concept of compendium. Unfortunately this stage is not reproducible unless data result from simulation experiments, a situation for which the reasoning already exposed can be applied without any modification. The approach followed in this book is to leverage on the capability of modern graphical rendering systems to automatically generate high quality imagery on which algorithms are trained and compared, thereby extending the application of reproducible research ideas to the complete data flow. The entire Appendix TM:B is devoted to the description of how synthetic, realistic images of complex objects can be generated. Data synthesis can then be regarded as an additional function and merging it with an active document does not require the introduction of any new concept or tool.