Fondazione Bruno Kessler - Technologies of Vision
contains material from
Template Matching Techniques in Computer Vision: Theory and Practice
Roberto Brunelli © 2009 John Wiley & Sons, Ltd
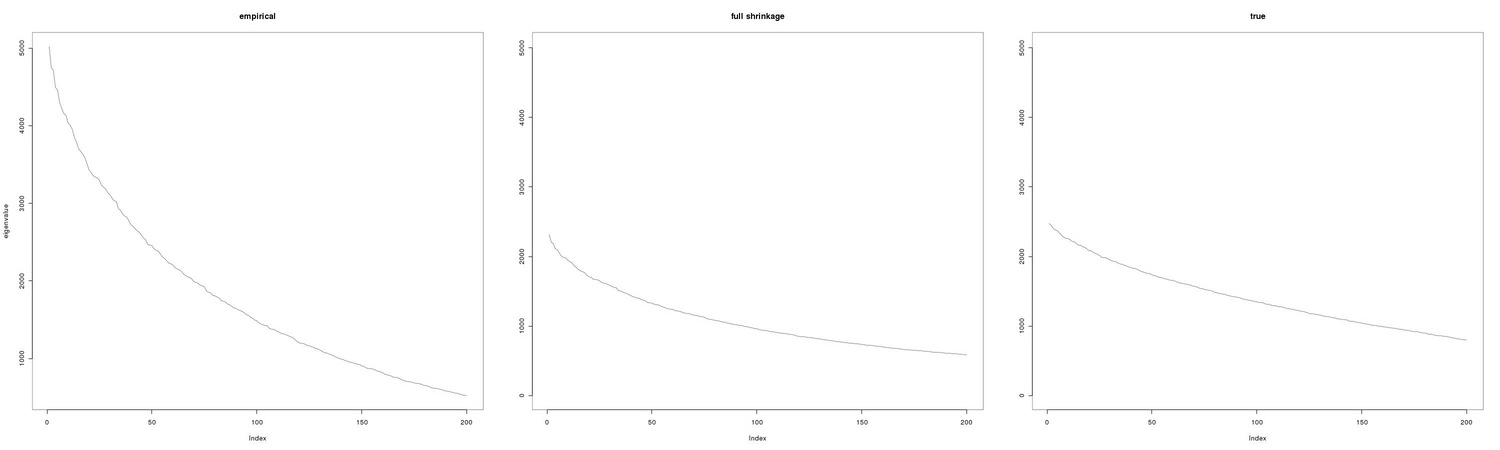
It may be worthwile to perform a simple simulation to check the potential advantage of using non standard estimators for the covariance matrix, the key quantity in PCA, in the case of large dimensionality and small number of samples.
Having generated our data sample we compute the covoriance matrix using the usual sample estimator and the shrinkage estimator:
and proceed to the computation of the eigenvalues:
As reported in Figure 8.4, the advatange of shrinkage estimators over the standard ones can be dramatic.